Sie fragen zuerst das Sprachmodell und hoffen, dass die Antwort richtig klingt.
Die Natur hat dieses Problem vor Millionen von Jahren gelöst.
In einem Bienenstock wird eine Entdeckung nicht zur Entscheidung, nur weil ein einzelner Akteur es sagt. Eine Späherbiene kehrt zum Stock zurück und tanzt eine Acht auf der vertikalen Wabenoberfläche — der Winkel des geraden Abschnitts zeigt die Richtung, die Dauer die Entfernung, die Intensität die Qualität. Aber der Tanz ist kein Monolog. Erfahrenere Schwestern folgen der Tänzerin, berühren sie mit ihren Fühlern und geben Echtzeit-Feedback. Ein Stoppsignal kann den Tanz vollständig beenden. Erst wenn die Nachricht die Prüfung der Gemeinschaft übersteht, entsteht eine Route, die es wert ist, verfolgt zu werden.
WaggleDance basiert auf dieser Logik.
Es übergibt das Problem nicht direkt an ein LLM. Es leitet es zuerst an den richtigen Solver weiter, verifiziert das Ergebnis durch mehrere Agenten und nutzt ein Sprachmodell nur dann, wenn es wirklich hilft. Jeder Schritt hinterlässt eine auditierbare Spur. Jede Lösung ist begründbar. Jeder Zyklus baut die eigene Expertise des Systems aus.
Der Achtertanz wurde zu algorithmischem Routing. Die Wabe wurde zur MAGMA-Speicherarchitektur. Und die nächtliche Ruhe der Bienen wurde zum Dream Mode — einer Simulation, in der das System die Fehler des Tages überprüft, Tausende alternativer Pfade testet und am nächsten Morgen klüger zurückkehrt.
Das ist keine Metapher. Das ist eine Architektur für kollektive Maschinenintelligenz.
Jetzt herunterladen, forken und lokal ausführen. Das gesamte Repository ist auf GitHub ohne Registrierung verfügbar.
Lizenzmodell: Apache 2.0 + BUSL 1.1 (offener Kern + quellverfügbare geschützte Module). Prüfen Sie die Bedingungen auf GitHub.
BUSL-Modul-Änderungsdatum: 18. März 2030.
Solver gehen zuerst. Der Verifizierer prüft. Das LLM kommt nur hinzu, wenn der richtige Solver nicht ausreicht.
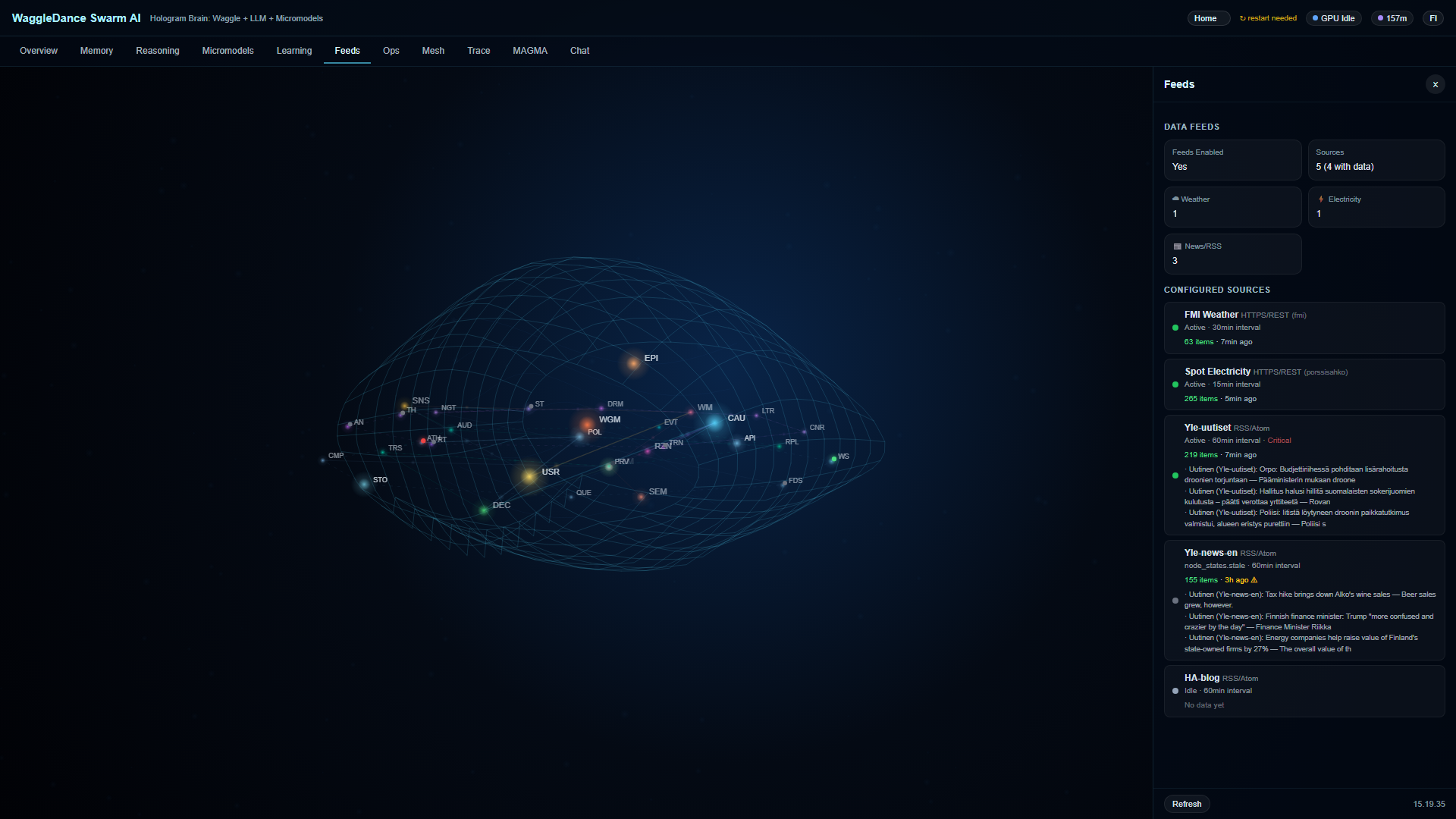
MAGMA zeichnet Entscheidungen, Quellen, Replays und Vertrauenswerte auf. Sehen Sie, was passiert ist, warum und in welcher Reihenfolge.
Dream Mode überprüft Fehler, simuliert bessere Routen und baut bessere Modelle für den nächsten Tag.
Hologram Brain macht den Zustand von 32 Knoten in Echtzeit sichtbar. Sie beobachten keine Black Box — Sie beobachten ein arbeitendes System.
Alles läuft in Ihrer eigenen Umgebung. Keine obligatorische Cloud, keine Prompt-Daten, die abfließen, keine SaaS-Abhängigkeit.
Dieselbe Codebasis funktioniert vom Raspberry Pi bis zum Fabrikprofil. Nicht nur eine Demo, nicht nur ein Framework.
RPi, Edge, Sensor
Offline, intermittierende Verbindung
Lokale Automatisierung
Überwachung, Anomalien, Audit
Dashboard und Hologram Brain sind sofort nach dem Start verfügbar. Die Geschwindigkeit der ersten Antwort hängt vom Profil, der Hardware und der Nutzung des Voll- oder Stub-Modus ab.
Der Prompt wird direkt an Grok gesendet — und als Backup in Ihre Zwischenablage kopiert
Grok öffnet sich in einem neuen Tab mit dem fertigen Prompt
Sie erhalten eine umfassende Analyse des Repositories, einen bewerteten Wettbewerbsvergleich und eine Fabrik-Bereitschaftsbewertung
Wenn das automatische Ausfüllen nicht funktioniert, fügen Sie manuell ein — der Prompt befindet sich bereits in Ihrer Zwischenablage.
Sie können denselben Prompt auch in Claude, ChatGPT oder jedem anderen LLM verwenden. Grok ist die Standardwahl auf dieser Seite.
Wenn Sie auf “Repository analysieren” klicken, führt die KI eine tiefgehende Analyse durch, die Folgendes umfasst:
Hauptbranch, Architektur, Module und neueste Commits
Was ist implementiert vs. was ist geplant oder angestrebt
Testabdeckung, praktische Reife und Produktionsbereitschaft
Speichermodell, Audit-Architektur, Provenienz und Vertrauensmechanismen
Bewertung 1-10 auf sechs Achsen vs Home Assistant, Node-RED, n8n, Open WebUI, LangGraph, AutoGen, CrewAI, Ollama
Industrielle Anwendungsfälle, Risiken, fehlende Integrationen, Bereitstellungsblocker
Klicken Sie auf einen Prompt, um ihn zu kopieren. Fügen Sie ihn für eine tiefere Erkundung in Ihre Grok-Sitzung ein.
Wählen Sie ein Profil und erhalten Sie einen maßgeschneiderten Bereitstellungsleitfaden von Grok.
Jedes der folgenden Tools ist gut in dem, was es tut. Der Vergleich soll zeigen, wie sich die Solver-first-Architektur von WaggleDance unterscheidet — nicht behaupten, dass die anderen schlecht sind.
clone → docker compose up -d — Ollama, Voikko (Finnish NLP), and the app all in one.Most workflow and local-LLM tools do not build a WaggleDance-style local, auditable learning trail by default. WaggleDance accumulates capability through solver evidence, MAGMA provenance, specialist models, Dream Mode simulations, and human-gated promotion. Illustrative projection, not a measured guarantee. Runtime promotion remains human-gated where safety requires it.
| Time | WaggleDance | Home Assistant | LangGraph | AutoGen/CrewAI | Node-RED/n8n | Ollama |
|---|---|---|---|---|---|---|
| Day 1 | LLM fallback ~30-50%, solvers learning | Same as always | Same as always | Same as always | Same as always | Same as always |
| Month 1 | HotCache fills, LLM ~20-30%, first canary promotions | No change | No change | No change | No change | No change |
| Month 6 | LLM ~10-15%, specialists maturing, ~180 nights of Dream Mode | No change | No change | No change | No change | No change |
| Year 1 | LLM ~5-8%, MAGMA with thousands of audited paths | No change | No change | No change | No change | No change |
| Year 2 | LLM <3-5%, >95% deterministic, TCO a fraction of day 1 | No change | No change | No change | No change | No change |
The competitors' column is empty everywhere except day 1. They don't learn. They don't improve. On day 730, they are exactly the same as on day 1.
Ja. Sofort herunterladen und ausführen. Apache-2.0-Teile sind frei nutzbar. Nicht-kommerzielle persönliche Nutzung der BUSL-geschützten Module ist erlaubt. Für kommerzielle Nutzung prüfen Sie die Lizenzbedingungen auf GitHub.
Nein. WaggleDance ist für den vollständig offline Betrieb auf lokaler Hardware konzipiert. Internet wird nur für die Ersteinrichtung und Updates benötigt.
Minimum: Raspberry Pi 4 oder Äquivalent (GADGET-Profil). Empfohlen: moderner x86-Server für Multi-Agenten-Orchestrierung (FACTORY-Profil).
Sie erhalten eine schnelle zweite technische Meinung zum öffentlichen Repository, zur Dokumentation und zur Wettbewerbslandschaft. Sie können denselben Prompt in Claude, ChatGPT oder jedem anderen LLM verwenden.
Ein Audit- und Provenienz-Framework. Jede Agenten-Entscheidung wird aufgezeichnet, sodass Sie Nachverfolgbarkeit, Replay und Sichtbarkeit der Vertrauensbewertung erhalten.
Ein nächtlicher Lernmodus, in dem das System die Fehler des Tages überprüft, bessere Routen simuliert und bessere Modelle für den nächsten Tag baut — automatisch ohne Benutzereingriff.
Dashboard und Hologram Brain sind sofort verfügbar. Die Geschwindigkeit der ersten Antwort hängt vom Profil und der Hardware ab.