Eles consultam o modelo de linguagem primeiro e esperam que a resposta pareça correta.
A natureza resolveu este problema há milhões de anos.
Numa colmeia, uma descoberta não se torna uma decisão porque um único ator assim o diz. Uma exploradora retorna à colmeia e dança uma figura em oito na superfície vertical do favo — o ângulo da seção reta indica a direção, a duração indica a distância, o vigor indica a qualidade. Mas a dança não é um monólogo. Irmãs mais experientes seguem a dançarina, tocam-na com as antenas e dão feedback em tempo real. Um sinal de parada pode interromper a dança por completo. Só quando a mensagem sobrevive ao escrutínio da comunidade é que surge uma rota que vale a pena seguir.
O WaggleDance é construído sobre esta lógica.
Ele não entrega o problema diretamente a um LLM. Encaminha-o primeiro para o solver correto, verifica o resultado através de múltiplos agentes e usa um modelo de linguagem apenas quando genuinamente ajuda. Cada passo deixa um rastro auditável. Cada solução é justificável. Cada ciclo aumenta a expertise do próprio sistema.
A dança em oito tornou-se roteamento algorítmico. O favo tornou-se a arquitetura de memória MAGMA. E o descanso noturno das abelhas tornou-se o Dream Mode — uma simulação onde o sistema revisa as falhas do dia, testa milhares de caminhos alternativos e retorna pela manhã mais sábio.
Isto não é uma metáfora. Esta é uma arquitetura para inteligência coletiva de máquinas.
Baixe, faça fork e execute localmente agora mesmo. O repositório completo está disponível no GitHub sem registro.
Modelo de licença: Apache 2.0 + BUSL 1.1 (núcleo aberto + módulos protegidos com código-fonte disponível). Verifique os termos no GitHub.
Data de alteração do módulo BUSL: 18 de março de 2030.
Os solvers vão primeiro. O verificador confere. O LLM só entra quando o solver correto não é suficiente.
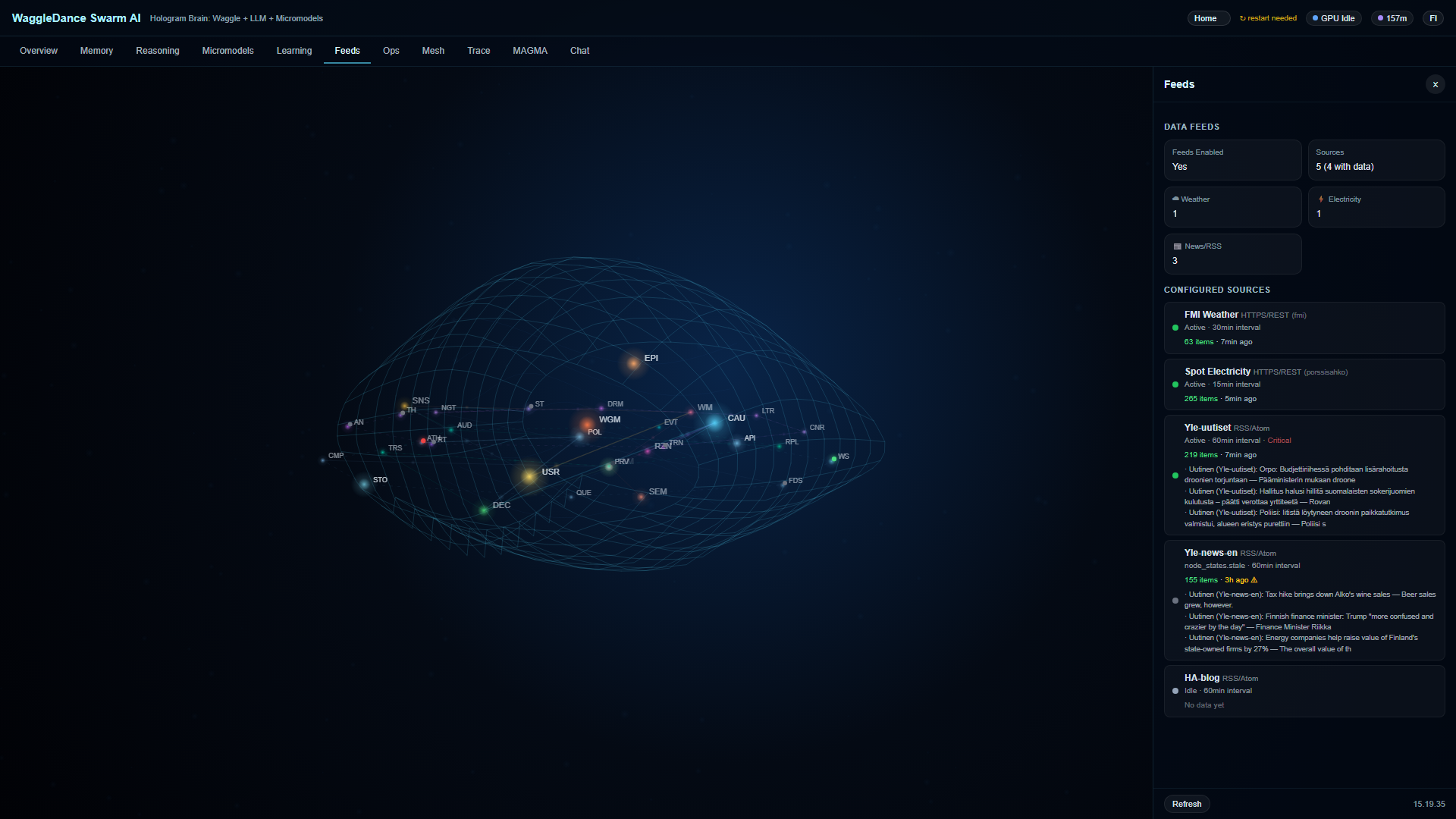
O MAGMA registra decisões, fontes, replays e pontuações de confiança. Veja o que aconteceu, por que e em que ordem.
O Dream Mode revisa falhas, simula melhores rotas e constrói modelos melhores para o dia seguinte.
O Hologram Brain torna o estado de 32 nós visível em tempo real. Você não está vendo uma caixa preta — está vendo um sistema funcionando.
Tudo roda no seu próprio ambiente. Sem nuvem obrigatória, sem dados de prompt saindo, sem dependência de SaaS.
O mesmo código funciona do Raspberry Pi ao perfil de fábrica. Não é apenas um demo, não é apenas um framework.
RPi, edge, sensor
Offline, conexão intermitente
Automação local
Monitoramento, anomalias, auditoria
O painel e o Hologram Brain ficam disponíveis imediatamente após a inicialização. A velocidade da primeira resposta depende do perfil, do hardware e do modo completo ou stub utilizado.
O prompt é enviado diretamente ao Grok — e copiado para sua área de transferência como backup
O Grok abre em uma nova aba com o prompt pronto
Você recebe uma análise abrangente do repositório, uma comparação pontuada com concorrentes e uma avaliação de prontidão para fábrica
Se o preenchimento automático não funcionar, cole manualmente — o prompt já está na sua área de transferência.
Você também pode usar o mesmo prompt no Claude, ChatGPT ou qualquer outro LLM. O Grok é a escolha padrão nesta página.
Quando você clica em “Analisar Repositório”, a IA realiza uma análise profunda cobrindo:
Branch principal, arquitetura, módulos e commits mais recentes
O que está implementado vs. o que é planejado ou aspiracional
Cobertura de testes, maturidade prática e prontidão para produção
Modelo de memória, arquitetura de auditoria, proveniência e mecanismos de confiança
Pontuação de 1-10 em seis eixos vs Home Assistant, Node-RED, n8n, Open WebUI, LangGraph, AutoGen, CrewAI, Ollama
Casos de uso industriais, riscos, integrações ausentes, bloqueadores de implantação
Clique em um prompt para copiá-lo. Cole na sua sessão do Grok para exploração mais profunda.
Escolha um perfil e obtenha um guia de implantação personalizado do Grok.
Cada ferramenta abaixo é boa no que faz. A comparação visa mostrar como a arquitetura solver-first do WaggleDance difere — não afirmar que as outras são ruins.
clone → docker compose up -d — Ollama, Voikko (Finnish NLP), and the app all in one.Most workflow and local-LLM tools do not build a WaggleDance-style local, auditable learning trail by default. WaggleDance accumulates capability through solver evidence, MAGMA provenance, specialist models, Dream Mode simulations, and human-gated promotion. Illustrative projection, not a measured guarantee. Runtime promotion remains human-gated where safety requires it.
| Time | WaggleDance | Home Assistant | LangGraph | AutoGen/CrewAI | Node-RED/n8n | Ollama |
|---|---|---|---|---|---|---|
| Day 1 | LLM fallback ~30-50%, solvers learning | Same as always | Same as always | Same as always | Same as always | Same as always |
| Month 1 | HotCache fills, LLM ~20-30%, first canary promotions | No change | No change | No change | No change | No change |
| Month 6 | LLM ~10-15%, specialists maturing, ~180 nights of Dream Mode | No change | No change | No change | No change | No change |
| Year 1 | LLM ~5-8%, MAGMA with thousands of audited paths | No change | No change | No change | No change | No change |
| Year 2 | LLM <3-5%, >95% deterministic, TCO a fraction of day 1 | No change | No change | No change | No change | No change |
The competitors' column is empty everywhere except day 1. They don't learn. They don't improve. On day 730, they are exactly the same as on day 1.
Sim. Baixe e execute imediatamente. As partes Apache 2.0 são de uso livre. O uso pessoal não comercial dos módulos protegidos por BUSL é permitido. Para uso comercial, verifique os termos da licença no GitHub.
Não. O WaggleDance foi projetado para funcionar totalmente offline em hardware local. A internet só é necessária para a configuração inicial e atualizações.
Mínimo: Raspberry Pi 4 ou equivalente (perfil GADGET). Recomendado: servidor x86 moderno para orquestração multi-agente (perfil FACTORY).
Você obtém uma rápida segunda opinião técnica sobre o repositório público, documentação e cenário competitivo. Pode usar o mesmo prompt no Claude, ChatGPT ou qualquer outro LLM.
Um framework de auditoria e proveniência. Cada decisão de agente é registrada para que você tenha rastreabilidade, replay e visibilidade da avaliação de confiança.
Um modo de aprendizado noturno onde o sistema revisa as falhas do dia, simula melhores rotas e constrói modelos melhores para o dia seguinte — automaticamente sem ação do usuário.
O painel e o Hologram Brain ficam disponíveis imediatamente. A velocidade da primeira resposta depende do perfil e do hardware.